Distributed Reasoning Plane
AnamDB is built to scale from a single-node embedded database kernel to a distributed multi-agent reasoning plane.
In distributed setups, the database coordinates neural perception and symbolic reasoning workloads across heterogeneous clusters.
The 5-Stage Symbolic Integration Pipeline
Every query execution is divided into five distinct stages to maximize optimization and concurrency:
- Stage 1 — Data Preprocessing: Row columns are read from Lance storage and transposed into vector-symbolic Arrow layouts.
- Stage 2 — Neural-Symbolic Embedding: Features are extracted and inference is run on ONNX models with first-order logic constraints.
- Stage 3 — Domain Knowledge: Intermediary scores are cross-referenced and augmented using active domain ontologies.
- Stage 4 — Logical Reasoning: The logic engine applies active Datalog rules over neural outputs and ontology mappings.
- Stage 5 — Symbolic Postprocessing: Final constraints, BCNF compliance, and schema requirements are verified before result compilation.
BCNF Policy Catalog
All rules and constraints are stored in a strict Boyce-Codd Normal Form (BCNF) database catalog.
- Incremental Replication: Updates, additions, or deprecations of Datalog rules are propagated throughout the cluster via version-stamped changeset deltas.
- Conflict Resolution: Version-stamps guarantee that all nodes evaluate queries against the exact same logic snapshot, preventing state drift during query execution.
Multi-Agent Task Router
The task router maps execution stages and model operators to the most suitable physical hardware in the cluster:
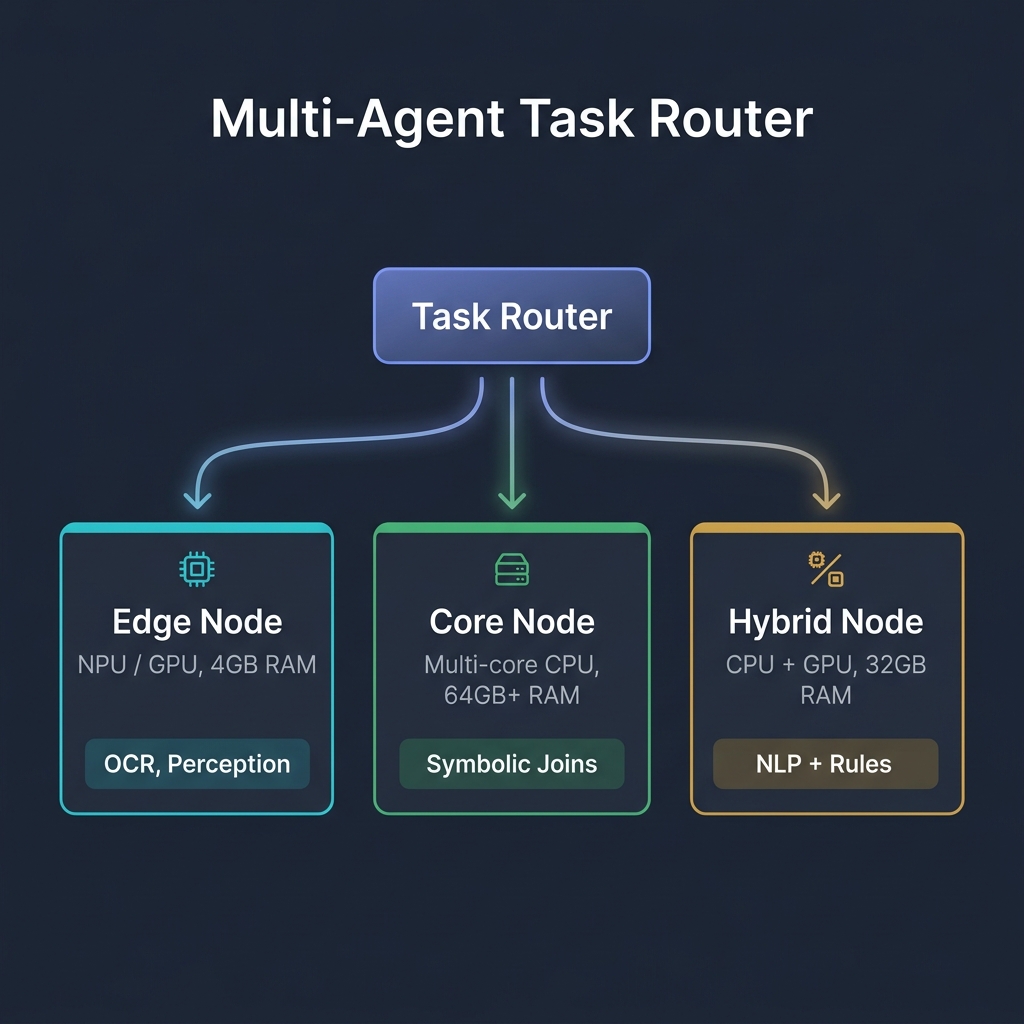
Cluster workloads are distributed based on node capabilities:
| Node Type | Resources | Ideal Workload | Description |
|---|---|---|---|
| Edge Node | NPU / GPU, 4GB RAM | Perception (OCR, Audio) | Runs lightweight model inference directly where data is ingested. |
| Core Node | Multi-core CPU, 64GB+ RAM | Symbolic Joins (Datalog) | Executes memory-intensive relational aggregates and constraint logic. |
| Hybrid Node | CPU + CUDA GPUs, 32GB RAM | Mixed (NLP + Datalog) | Performs complex NLP processing followed by logic rules. |
Network-Aware Distributed Optimizer
When executing across a network, the multi-objective Pareto optimizer incorporates network overhead (data serialization and transfer times) alongside compute latencies:
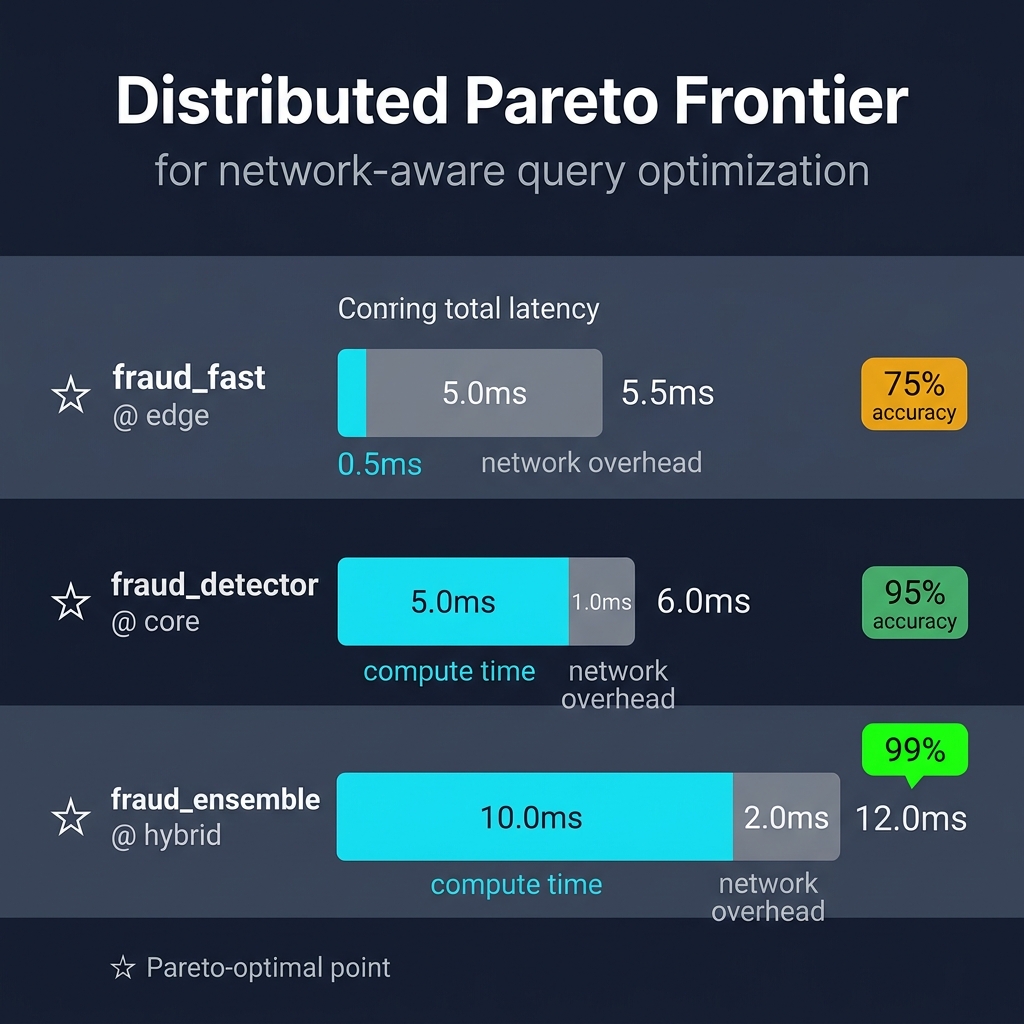
Progressive Query Rewrite
If a remote edge node becomes congested at runtime or network latency spikes, the coordinator dynamically rewrites the physical query plan. It transparently shifts the perception operator to a base model on a core node to satisfy the query's latency constraint without returning failure.
Global Lineage
Global lineage traces results across physical cluster hops. Developers can inspect the exact pathway a tuple traveled, which models processed it, and how confidence scores fluctuated:
